译自IBM Developerworks
Thanks for the memory, Linux
Understanding how the JVM uses native memory on Windows and Linux
原文链接
前言
Java堆是我们在写程序时最常用的内存区域,它是存放所有Java对象的位置(译者注:现在未逃逸对象已经使用了栈上分配)。JVM旨在使我们不受主机特性的影响,所以在探讨内存的时候,很自然的就会想起堆内存。毫无疑问,你肯定遇到过由于对象泄漏或者堆内存过小导致的堆内存溢出,并且可能已经掌握了一些调试相关问题的手段。但是,当使用使用Java处理更多数据和更多并发时,你可能会遇到无法使用常规手段修复的内存溢出错误,即使堆内存未满,也会抛出错误(OutOfMemoryError)的情况。发生这种情况时,你需要了解Java运行时环境(JRE)内部的情况。
Java应用在Java运行时的虚拟化环境中运行,但运行时本身也是用编程语言(例如C)开发的、使用native资源(包括内存)的程序。与Java应用使用的Java堆内存不同,native内存是系统运行时进程可用的内存。所有虚拟资源(包括Java堆和Java线程)都必须与虚拟机运行时使用的数据一起存储在native内存中。这意味着宿主机硬件和操作系统对native内存的限制会影响使用者对Java应用的操作。
本文是在不同平台上涵盖相同主题的两篇文章之一。这两者中,你将了解native内存是啥,Java运行时如何使用它,它看起来是啥,以及如何调试native内存溢出错误。本文主要介绍在Windows和Linux平台,并不关注任何特定的运行时(JVM)实现。配套文章介绍了AIX,重点介绍了IBM®DeveloperKit for Java。 (该文章中关于IBM实现的信息对于AIX以外的平台也是如此,因此如果你在Linux上使用IBM Developer Kit for Java或者在IBM 32位Runtime Environment for Windows上,可能会发现该文章也很有用。)
回顾native内存
首先,我将解释操作系统和底层硬件对native内存的限制。如果你比较熟悉编程语言管理动态内存(例如C语言),可以直接跳到下一部分。
硬件限制
Native进程的许多限制是由硬件而不是操作系统引起的。每台计算机都有一个处理器和一些内存(RAM)。处理器拥有有一个或多个处理单元,将数据流解释为要执行的指令,执行整数、浮点运算以及其他高级计算。处理器有许多寄存器,用作执行计算的工作存储器;寄存器大小决定了单个计算可以使用的最大容量。
处理器通过存储器总线连接到物理存储器。物理地址长度(处理器用于索引物理RAM的地址)限制了可以寻址的内存数量。例如,16位物理地址可以从0x0000到0xFFFF寻址,包括2 ^ 16 = 65536个唯一的存储单元。如果每个地址引用一个存储字节,则16位物理地址将允许处理器寻址64KB的存储器。
可以使用一定数量的位来描述处理器。这取决于寄存器的大小,但有例外(比如390 31位)其中它指的是物理地址长度。对于桌面和服务器平台,一般是31、32或64位;对于嵌入式设备和微处理器,可以低至4位。物理地址大小可以与寄存器位宽相等,也可以更大或更小。对于兼容的操作系统来说,大多数64位处理器可以运行32位程序。
表1列出了一些流行的Linux版本和Windows架构及其寄存器位宽和物理地址长度:
| 架构 |
寄存器位宽(bits) |
物理地址长度(bits) |
| (现代)英特尔X86 |
32 |
32
36使用物理地址扩展(奔腾Pro及更高版本) |
| x86 64 |
64 |
目前48位(范围后期会增加) |
| PPC64 |
64 |
在POWER 5上为50位 |
| 390 31-bit |
32 |
31 |
| 390 64-bit |
64 |
64 |
表1.一些常用处理器架构的寄存器位宽和物理地址长度
操作系统与虚拟内存
对于不使用操作系统的程序来说,可以使用处理器寻址范围内的所有内存。但是为了享受多任务和硬件抽象等功能,大部分开发者还是会使用操作系统。
在Windows和Linux等多任务操作系统中,许多程序共用包括内存在内的系统资源。每个程序都需要分配物理内存才能工作。理想情况下,可以设计这样一个操作系统,使每个程序可以直接使用物理内存,并且保证只使用由系统分配的内存。一些嵌入式操作系统的工作方式就类似这样,但在由多个未经过集成测试的程序组成的环境中并不实用,因为任何程序都可能破坏其他程序或操作系统本身的内存。
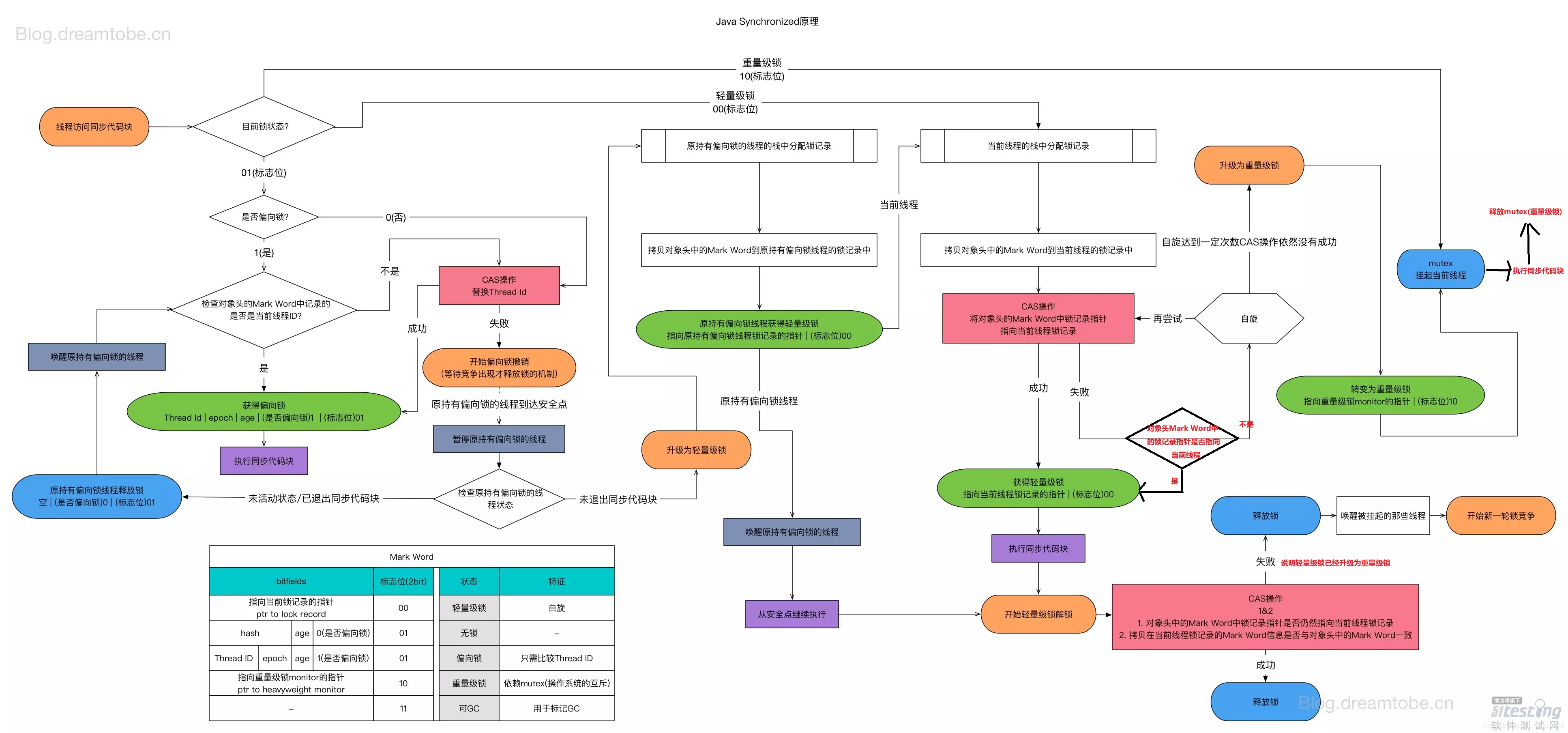
虚拟内存允许多个进程共享物理内存,而且不会破坏彼此的数据。在使用虚拟内存的操作系统(例如Windows,Linux等其他操作系统)中,每个程序都有自己的虚拟地址空间:物理地址的逻辑区域,其大小由该系统的地址长度决定(31,32或桌面和服务器平台的64位)。进程中的虚拟地址空间可以映射到物理内存、文件或任何其他可寻址存储设备。操作系统可以将物理内存中数据移入和移出交换区域(Windows上的页面文件或Linux上的交换分区),以便充分利用物理内存。当程序试图使用虚拟地址访问存储器时,OS与片上硬件结合将该虚拟地址映射到物理位置。该位置可以是物理RAM,文件或页面文件/交换分区。如果已将某片内存区域移动到交换空间,则在使用之前将会把它重新加载到物理内存中。图1展示了虚拟内存通过进程地址空间映射以实现共享资源的工作原理:
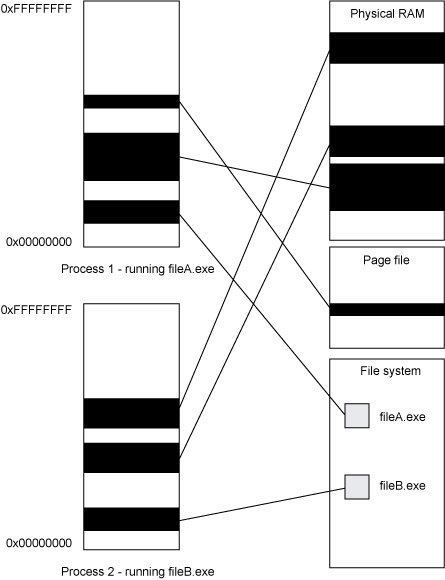
每个程序实例都会作为一个进程运行。Linux和Windows上的进程是有关操作系统控制的资源(例如文件和套接字)信息的集合,通常对应一个虚拟地址空间(在某些架构中大于一个),和至少一个执行线程。
虚拟地址长度可以小于处理器的物理地址长度。英特尔x86 32位最初有32位物理地址,允许处理器处理4GB存储空间。后来增加加了物理地址扩展(PAE)功能,把物理地址长度扩展到36位,支持安装和寻址最多64GB的RAM。PAE支持操作系统将32位4GB虚拟地址空间映射到更大的物理地址空间,但它并不支持每个进程具有64GB虚拟地址空间。即,如果在32位的英特尔服务器上使用超过4GB的内存,则无法把全部内存直接映射到单个进程中。
Address Windowing Extensions功能允许Windows进程将其32位地址空间的一部分作为滑动窗口映射到更大的内存区域。 Linux使用基于将区域映射到虚拟地址空间的类似技术。这意味着虽然用户无法直接引用超过4GB的内存,但可以使用更大的内存区域。
内核态与用户态
虽然每个进程都有自己的地址空间,但用户程序并不能全部使用。地址空间分为用户态和内核态。内核位于操作系统中,包含了计算机硬件接口、调度程序以及提供网络和虚拟内存等服务等功能。
作为计算机引导序列的一部分,操作系统内核运行并初始化硬件。一旦内核配置了硬件及其自身的内部状态,就会启动第一个用户态进程。如果用户程序需要使用操作系统提供的服务,它可以执行系统调用从而跳转到内核程序,然后内核程序执行请求。对于诸如读取和写入文件,联网以及启动新进程等操作,通常需要系统调用。
内核在执行系统调用时需要访问自己的内存和调用进程的内存。因为正在执行当前线程的处理器被配置为使用当前进程的地址空间映射来映射虚拟地址,所以大多数操作系统将每个进程地址空间的一部分映射到公共内核存储器区域。映射供内核使用的地址空间部分称为内核态空间;可以由用户应用程序使用的其余部分称为用户态空间。
内核态和用户态空间的平衡因操作系统而异,甚至在不同硬件架构上运行的相同操作系统的实例之间也存在差异。这种平衡一般是可配置的,可为用户态程序或内核态程序提供更多空间。压缩内核态区域可能会导致诸如限制可以同时登录的用户数量或可以运行的进程数量等问题;较小的用户态空间则意味着供开发者使用的空间较小。
默认情况下,在32位Windows具有2GB的用户态空间和2GB的内核态空间。某些Windows版本上,通过将/3GB*配置项开关添加到引导配置并使用/LARGEADDRESSAWARE*配置项开关重新链接应用程序,可以将用户态空间配置为3GB,内核空间为1GB。在32位Linux上,默认用户态空间为3GB和内核态空间为1GB。有些Linux发行版提供了一种名为hugemem,支持4GB用户态空间的内核。为实现此目的,内核拥有自己的地址空间,用于进行系统调用。在这种情况下,虽然用户态空间变大了,但系统调用变的更慢,因为操作系统必须在用户态和内核态的地址空间之间复制数据,并在每次进行系统调用时重置进程地址空间映射。图2展示了32位Windows的地址空间布局:
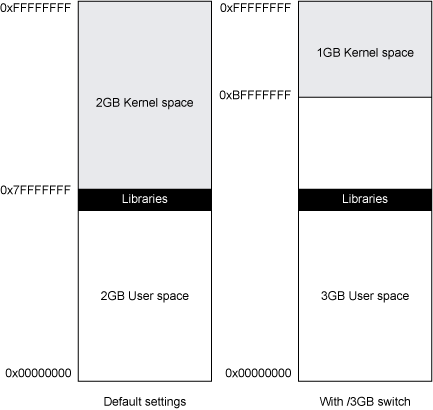
图3显示了32位Linux的地址空间布局:
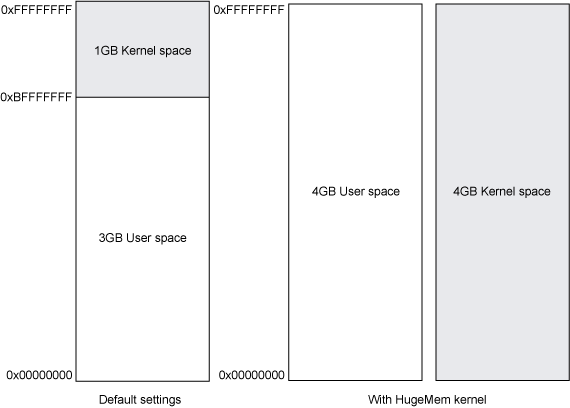
对于Linux 390 31位架构,使用单独的内核地址空间使得对于小于2GB的地址空间并不适合划分独立地址空间;但是390架构可以在工作同时使用多个地址空间而不会影响性能。
进程地址空间必须包含程序所需的所有内容:包括程序本身和它使用的共享库(Windows上的DLL,Linux上的.so文件)。共享库不仅可以占用程序不能存储数据的空间,还能分割地址空间并减少可以作为连续块分配的内存。这在使用3GB用户态空间的Windows x86上运行的程序中很明显。 DLL是由首选的加载地址构建的:当加载DLL时,它被映射到特定位置的地址空间,除非该位置已被占用,此时,它会被重新定位并加载到其他位置。最初设计Windows NT时,用户态空间为2GB,系统库被加载至2GB的边界附近,从而使大部分用户态空间可供用户程序使用。当用户态空间扩展到3GB时,系统共享库仍然加载到2GB附近:位于用户空间的中间。虽然总用户态空间为3GB,但无法分配3GB的内存块,因为中间还隔着共享库。
在Windows上使用/3GB*开关可将内核空间减少到原先设计的一半(1GB)。在某些情况下,可能在耗尽1GB内核态空间时遇到慢I/O或创建新用户会话的问题。虽然/3GB*开关对某些应用程序非常有价值,但使用它的任何环境都应在部署之前进行全面的压力测试。
Native内存泄漏或使用太多的native内存使用会导致不同的问题,具体取决于是否耗尽地址空间或物理内存。耗尽地址空间通常只发生在32位的进程中:因为最大4GB很容易分配。64位进程有成百上千GB的用户态空间,所以很难耗尽。如果你耗尽了Java进程的地址空间,Java运行时就会出现我将在本文后面描述的奇怪症状。在进程地址空间比物理内存更大的系统上运行时,内存泄漏或过度使用native内存会强制操作系统将某些native进程的虚拟地址空间交换至外存。访问已被交换的内存地址比读取驻留(物理内存)地址要慢得多,因为操作系统必须从硬盘驱动器读取数据。为了可以分配足够的内存,可能耗尽所有物理内存和交换分区(页面文件);在Linux上,这会触发内核内存不足(OOM)杀手,它会强行杀死占用大量内存的进程。在Windows上,分配开始失败的方式与地址空间已满时的方式相同。
如果你使用的虚拟内存比物理内存更大,很明显,在进程因为内存耗尽而被杀死之前很久就会出现问题。系统会停止响应:大部分时间都用于在交换空间和物理内存之间来回复制。发生这种情况时,计算机和各个应用程序的性能将变得非常差。当JVM的Java堆被交换出时,GC的性能变得极差,以至于程序好像挂起了。如果在同一台计算机上运行多个Java程序实例时,物理内存必须足以容纳所有Java堆。
Java运行时如何使用native内存
Java运行时是操作系统中的进程,它受到作者在前一节中概述的硬件和操作系统限制的约束。运行时环境提供了由未知代码驱动的功能,所以无法预测运行时环境在每种情况下都需要哪些资源。 在Java环境中,Java应用程序执行的每个操作都可能会影响提供该环境的运行时资源需求。本节介绍Java应用程序使用native内存的方式和以及为啥要这样用。
堆与GC
Java堆是分配对象的内存区域。大多数Java SE实现都有一个逻辑堆,尽管一些专业Java运行时(例如Java实时规范(RTSJ))有多个堆。根据用于管理堆内存的垃圾收集(GC)算法,可以将单个物理堆拆分为逻辑部分。这些部分通常由被Java内存管理器(包括垃圾收集器)管理,native内存的连续区域实现。
在Java命令行中,-Xmx和-Xms选项可以控制堆大小(mx是堆的最大大小,ms是初始大小)。虽然逻辑堆大小可以根据堆上对象数量和GC消耗的时间来控制,但使用的native内存数量是不变的。由于大部分GC算法依赖于连续的内存块,因此堆需要扩展时,无法分配更多native内存,All heap memory must be reserved up front。
Reserving native memory is not the same as allocating it. When native memory is reserved, it is not backed with physical memory or other storage. Although reserving chunks of the address space will not exhaust physical resources, it does prevent that memory from being used for other purposes. A leak caused by reserving memory that is never used is just as serious as leaking allocated memory.
Some garbage collectors minimise the use of physical memory by decommitting (releasing the backing storage for) parts of the heap as the used area of heap shrinks.
More native memory is required to maintain the state of the memory-management system maintaining the Java heap. Data structures must be allocated to track free storage and record progress when collecting garbage. The exact size and nature of these data structures varies with implementation, but many are proportional to the size of the heap.
即时编译(JIT)
JIT编译器在运行时将Java字节码编译为优化的native可执行代码。这极大地提高了Java运行时的运行时速度,并允许Java应用程序以与native代码一样的速度运行。
字节码编译使用native内存(与gcc等静态编译器需要运行内存的方式相同),但JIT的输入(字节码)和输出(可执行代码)也必须存储在native内存中。包含许多JIT编译方法的Java应用程序比较小的应用程序使用更多的native内存。
类和类加载器
Java应用程序由定义对象结构和方法逻辑的类组成。它们还使用Java运行时类库(例如java.lang.String)中的类,并且可以使用第三方库。只要它们被使用,这些类就需要存储在内存中。
如何存储类因实现而异。Sun JDK使用堆中的永久代(PermGen)。Java 5以后的IBM实现为每个类加载器分配native内存块,并将类数据存储在里面。现代Java运行时具有诸如类共享之类的技术,这些技术可能需要将共享内存映射到地址空间。要了解这些分配机制如何影响Java运行时的本机占用空间,可以阅读该实现的官方文档。但这些实现仍然存在共同点。
在最基本的层面上,使用更多类会占用更多内存。这可能意味着您的native内存使用量增加,或者您必须显式调整某个区域的大小:比如永久代或共享类缓存,以便足够存放所有类。请记住,不仅是程序需要足够的内存;框架、应用程序服务器、第三方库和Java运行时都包含有按需加载而且占用内存的类。
Java运行时可以卸载类来回收空间,但只能在严格的条件下进行。不可能卸载单个类。卸载类加载器,取出它们加载的所有类。只有在以下情况下才能卸载类加载器:
- Java堆没有该类加载器(java.lang.ClassLoader)的实例。
- Java堆没有由该类加载器加载的java.lang.Class的实例。
- 该类加载器加载的任何类的对象都不在Java堆上存活(引用)。
注意,Java运行时为所有Java应用程序设置的三个默认类加载器: bootstrap、extension和application均不满足这些标准;因此,任何系统类(如java.lang.String)或者通过application类加载器加载的任何应用程序类都无法在运行时释放。
即使类加载器符合垃圾回收条件,运行时也只会将类加载器作为GC循环的一部分进行收集。某些实现仅在某些GC周期中卸载类加载器。
在没有意识到的情况下,也可以在运行时生成类。许多J2EE应用程序使用JavaServer Pages(JSP)技术来生成Web页面。使用JSP为每个执行的.jsp页面生成一个类,因此,会延长加载这些类的类加载器的生命周期:通常是Web应用程序的生命周期。
生成类的另一种常用方法是使用Java反射。反射的工作方式因Java实现而异,但Sun和IBM实现都使用下面的方法。
使用java.lang.reflect API时,Java运行时必须将反射对象(如java.lang.reflect.Field)的方法连接到反射的对象或类。这可以通过使用Java native接口(JNI)访问器来完成,该访问器使用方便但速度很慢,或者在运行时为要反射的对象动态生成所需类。第二种方法使用麻烦但执行速度快,因此非常适合经常使用反射技术的应用程序。
Java运行时在反射类的前几次使用JNI方法,但在多次使用之后,访问器被扩展为字节码访问器,这样需要构建相关类并用新的类加载器加载。大量反射可能会导致创建许多访问器类和类加载器。保持对反射对象的引用会使这些类保持活跃并继续占用空间。因为创建字节码访问器非常慢,所以Java运行时可以缓存这些访问器供以后使用。某些应用程序和框架还会缓存反射对象,因此也会占用native内存。
JNI
JNI允许native代码(使用native编译语言,如C和C++编写的应用程序)调用Java方法,反之亦然。Java运行时本身在很大程度上依赖于JNI代码来实现类库函数,例如文件和网络I/O. JNI应用程序可以通过三种方式增加Java运行时占用的native内存:
- JNI应用程序的本机代码被编译为加载到进程地址空间的共享库或可执行文件。大型native应用程序只需加载就可占据很大一部分进程地址空间。
- Native代码必须与Java运行时共享地址空间。
- 某些JNI函数可以使用native内存作为其正常操作的一部分。GetTypeArrayElements和GetTypeArrayRegion函数可以将Java堆数据复制到native内存缓冲区,以便使用native代码。是否复制取决于运行时实现。(IBM Developer Kit for Java 5.0及更高版本生成native副本。)以这种方式访问Java堆中的大量数据可能会使用相应数量的native堆。
NIO
Java 1.4中添加的新I/O(NIO)相关类引入了基于通道和缓冲区的新I/O方法。除了基于Java堆内存实现的I/O缓冲区之外,NIO还添加了对native内存实现的的DirectByteBuffers(使用java.nio.ByteBuffer.allocateDirect()方法分配)的支持。DirectByteBuffers可以直接传递给操作系统库函数来执行I/O:某些情况下这样做明显速度更快,因为可以避免在Java堆和native堆之间复制数据(即零拷贝,译者注)。
那么,DirectByteBuffer数据究竟在哪里存储?应用程序仍然使用Java堆上的对象来编排I/O操作,但带有数据的缓冲区在native内存中:Java堆对象仅包含对native堆缓冲区的引用。非直接的ByteBuffer将其数据保存在Java堆上的byte数组中。图4显示了直接和非直接ByteBuffer对象之间的区别:
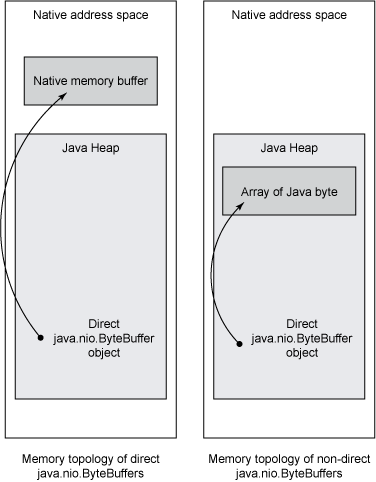
DirectByteBuffer对象自动清理其对应的native缓冲区,但只能作为Java堆GC的一部分执行:因此它们不会自动响应native堆上的压力。GC仅在Java堆变满时才会发生:无法继续分配内存时,或者Java应用程序显式调用,并不推荐显示调用,因为会导致性能问题(译者注,Full GC会导致STW)。
极端情况下,native堆已满并且一个或多个DirectByteBuffers符合GC条件(可以在native堆中释放空间),但由于Java堆还没有满,所以不会GC。
线程
程序中的每个线程都需要内存来存储其堆栈(用于保存局部变量的内存区域以及调用函数时的状态)。每个Java线程都需要运行堆栈空间。根据实现,Java线程可以具有单独的native和Java堆栈。除了堆栈空间之外,每个线程还需要一些native内存用于thread-local存储和内部数据结构。
栈大小因Java实现和架构而异。某些实现可以指定Java线程的栈大小。通常在256KB和756KB之间。
尽管每个线程使用的内存量非常小,但对于具有数百个线程的程序,线程栈的总内存使用量可能很大。当程序中的线程数量比可用处理器数量多很多时,会导致效率降低和内存使用量增加。
如何判断我的native内存是否耗尽?
Java运行时处理Java堆内存耗尽和native堆内存耗尽的方式完全不同,尽管这两种情况都可能出现类似的症状。Java程序在Java堆耗尽时很难运行:因为Java应用程序很难在不分配对象的情况下执行任何操作。一旦Java堆填满,GC性能就会变得非常糟糕,并抛出OutOfMemoryErrors。
相反,一旦Java运行时启动并且程序处于稳定状态,就可以一直工作到native堆完全耗尽。不一定出现奇怪的行为(native堆耗尽时),因为需要分配native内存的操作比需要分配Java堆的操作要少得多。虽然需要分配native内存的操作因JVM实现而异,但一些常用示例包括:启动线程,加载类以及执行某些类型的网络和文件I/O.
Native内存不足时的症状比Java堆内存不足时的症状不尽相同,因为native堆的分配没有单一的控制入口。尽管所有Java堆分配都在Java内存管理系统的控制之下,但任何本机代码 :无论是在JVM内部,Java类库还是应用程序代码,都可以执行本机内存分配,并捕获错误。然后根据设计者的想法,相应代码然后可以处理该错误:它可以通过JNI接口抛出OutOfMemoryError,在控制台打印日志、静默失败并稍后再试、或者做一些其他的事情。
由于native内存耗尽的诸多症状并不典型,所以没有一种简单的办法可以确认native内存耗尽。所以,需要使用来自操作系统和Java运行时的数据来确认问题究竟出在哪里。
native内存耗尽的几个例子